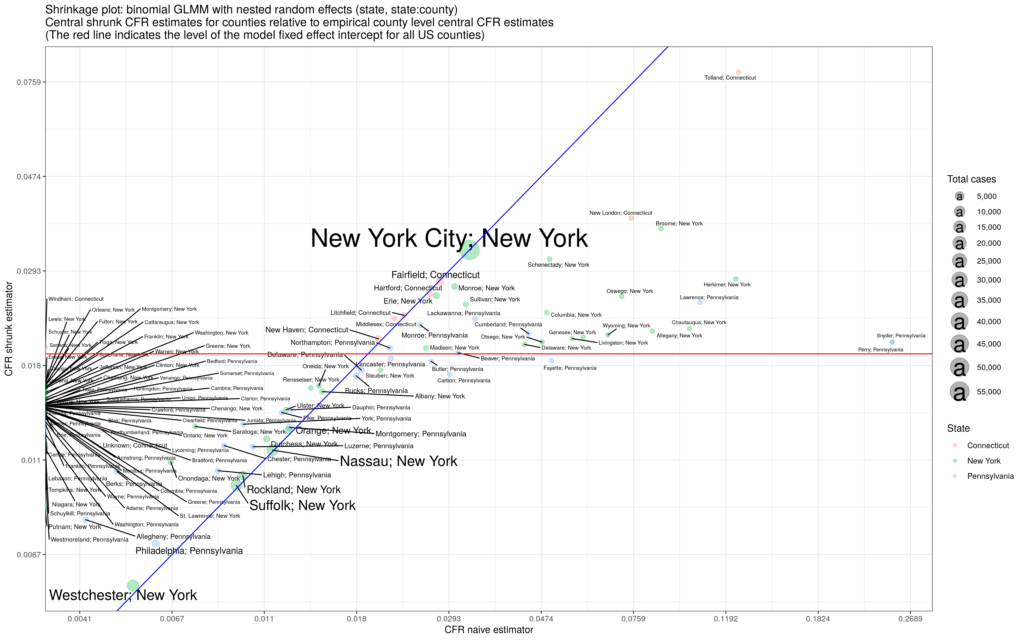
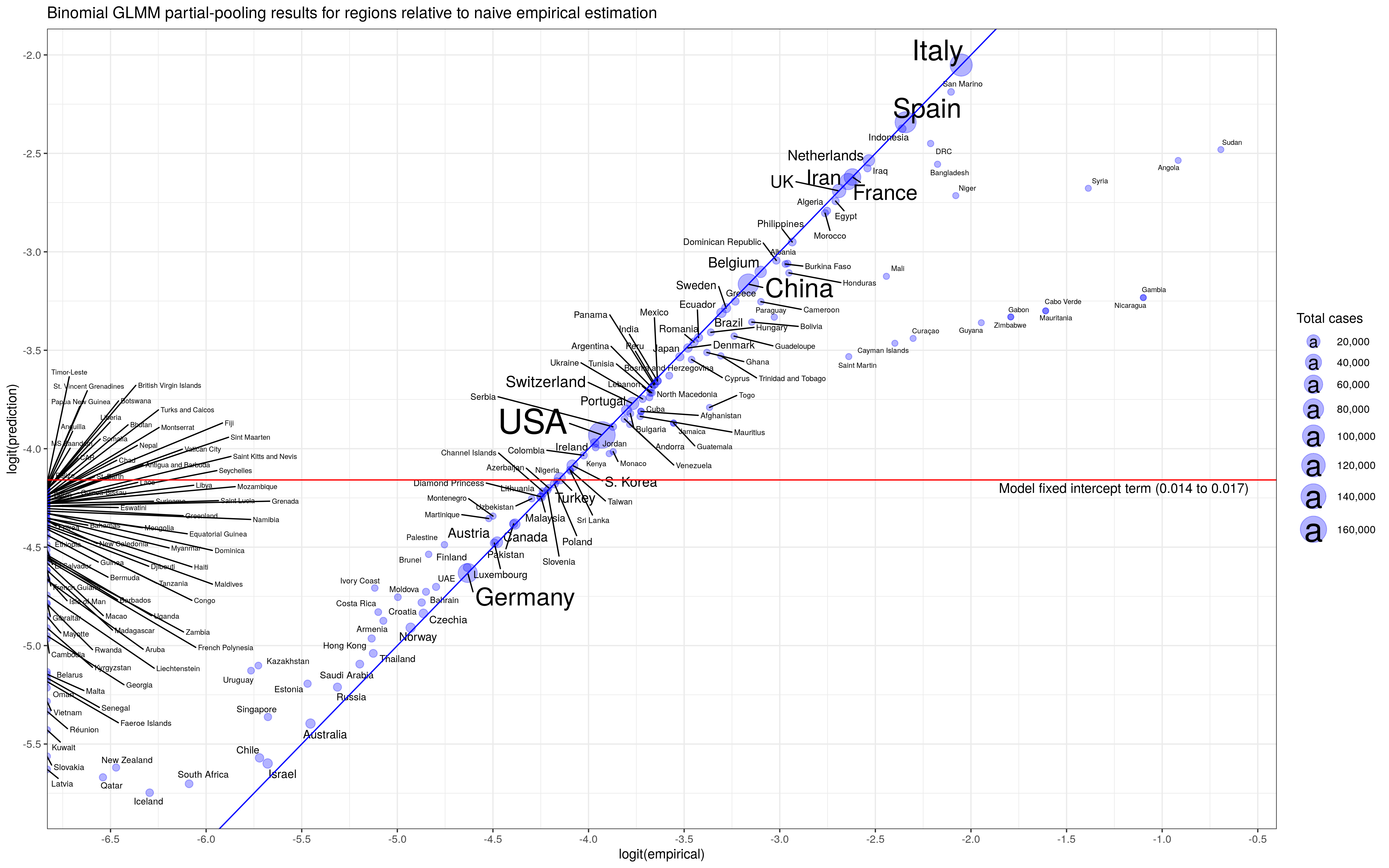
Three excellent essays recently appeared in the Boston Review by Jonathan Fuller, John Ioannidis, and Marc Lipsitch on the nature of epidemiology, and the use of data in making public health decisions. Each essay makes great points, especially Professor Ioannidis’ emphasis that Covid-19 public health decisions constitute trade-offs – other people will die based on our decisions to mitigate Covid-19. But I think all of all three essays miss the essential question, which transcends Covid-19 or even public health:
What is the optimal way to make irreversible decisions under uncertainty?
The answer to this question is subtle because it involves three competing elements: time, uncertainty, and irreversibility. In a decision making process, time gives us the opportunity to learn more about the problem and remove some of the uncertainty, but it’s irreversibility that makes the problem truly difficult. Most important problems tend to have a component of irreversibility. Once we make the decision, there is no going back or it is prohibitively expensive to do so, and our opportunity to learn more about the problem is over.
Irreversibility coupled with uncertainty and time means there is value in waiting. By acting too soon, we lose the opportunity to make a better decision, and by waiting too long, we miss the opportunity altogether. Waiting and learning incurs a cost, but that cost is often more than offset by the chance to make a better and more informed decision later. The value of waiting in finance is part of option pricing and that value radically changes optimal decision making. There is an enormous amount of research on option valuation with irreversible decisions. The book Investment Under Uncertainty by Avinash Dixit and Robert Pindyck provides a wonderful introduction to the literature. When faced with an irreversible decision, the option value can be huge, even dwarfing the payoff from immediate action. At times, learning is the most valuable thing we can do. But for the option to have value, we must have time to wait. In now-or-never situations, the option loses its value completely simply because we have no opportunity to learn. The take-a-way message is this: the more irreversible the decision, the more time you have, and the more uncertainty you face, the larger the option value. The option value increases along each of these dimensions, thereby increasing the value of waiting and learning.
Covid-19 has all of these ingredients – time, uncertainty, and irreversibility. Irreversibility appears through too many deaths if we wait too long, and economic destruction requiring decades of recovery if we are too aggressive in mitigation (while opening up global financial risks). There is a ton of uncertainty surrounding Covid-19 with varying degrees of limited time windows in which to act.
Those who call for immediate and strong Covid-19 mitigation strategies recognize irreversibility – we need to save lives while accepting large economic costs – and that even though we face enormous uncertainty, the costs incurred from waiting are so high compared to immediate action that the situation is ultimately now-or-never. There is no option value. Those who call for a more cautious and nuanced approach also see the irreversibility but feel that while the costs from learning are high and time is short, the option value is rescued by the enormous uncertainty. With high uncertainty, it can be worth a lot to learn even a little. Using the lens of option valuation, read these two articles by Professor Ioannidis and Professor Lipsitch from this March and you can see that the authors are actually arguing over the competing contributions of limited time and high uncertainty to an option’s value in an irreversible environment. They disagree on the value of information given the amount of time to act.
So who’s right? In a sense, both. We are not facing one uncertain irreversible decision; we face a sequence of them. When confronted by a new serious set of problems, like a pandemic, it can be sensible to down-weight the time you have and down-weight the uncertainty (by assuming the worst) at the first stage. Both effects drive the option value to zero – you put yourself in the now-or-never condition and you act. But for the next decision, and the next one after that, with decreasing uncertainty over time, you change course, and you use information differently by recognizing the chain of decisions to come. Johan Giesecke makes a compelling argument about the need for a course change with Covid-19 by thinking along these lines.
While option valuation can help us understand the ingredients that contribute to waiting, the uncertainty must be evaluated over some probability measure, and that measure determines how we weigh consequences. There is no objectively correct answer here. How do we evaluate the expected trade-off between excess Covid-19 deaths among the elderly vs a lifetime of lost opportunities for young people? How much extra child abuse is worth the benefit of lockdowns? That weighing of the complete set of consequences is part of the totality of evidence that Professor Ioannidis emphasizes in his essay.
Not only does time, uncertainty, and irreversibility drive the option value, but so does the probability measure. How we measure consequences is a value judgment, and in a democracy that mesaure must rest with our elected officials. It’s here that I fundamentally disagree with Professor Lipsitch. In his essay, he increasingly frames the philosophy of public health action in terms of purely scientific questions. But public action, the decision to make one kind of costly trade-offs against another – and it’s always about trade-offs – is a deeply political issue. In WWII, President Truman made the decision to drop the bomb, not his generals. Science can offer the likely consequences of alternative courses of public health actions, but it is largely silent on how society should weigh them. No expert, public health official, or famous epidemiologist has special insight into our collective value judgment.